AUTONOMIC COMPUTING
Autonomic computing is a self-managing computing model named after, and patterned on, the human body’s autonomic nervous system. An autonomic computing system would control the functioning of computer applications and systems without input from the user, in the same way that the autonomic nervous system regulates body systems without conscious input from the individual. The goal of autonomic computing is to create systems that run themselves, capable of high-level functioning while keeping the system’s complexity invisible to the user.
Autonomic computing is one of the building blocks of pervasive computing, an anticipated future computing model in which tiny – even invisible – computers will be all around us, communicating through increasingly interconnected networks. Many industry leaders, including IBM, HP, Sun, and Microsoft are researching various components of autonomic computing. IBM’s project is one of the most prominent and developed initiatives. In an effort to promote open standards for autonomic computing, IBM recently distributed a document that it calls “a blueprint for building self-managing systems,” along with associated tools to help put the concepts into practice. Net Integration Technologies advertises its Nitix product as “the world’s first autonomic server operating system.”
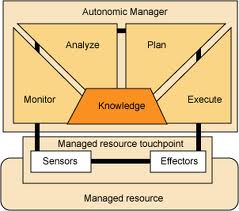
Autonomic Computing refers to the self-managing characteristics of distributed computing resources, adapting to unpredictable changes while hiding intrinsic complexity to operators and users. An autonomic system makes decisions on its own, using high-level policies; it will constantly check and optimize its status and automatically adapt itself to changing conditions. An autonomic computing framework is composed of autonomic components (AC) interacting with each other. An AC can be modeled in terms of two main control loops (local and global) with sensors (for self-monitoring), effectors (for self-adjustment), knowledge and planner/adapter for exploiting policies based on self- and environment awareness.
A general problem of modern distributed computing systems is that their complexity, and in particular the complexity of their management, is becoming a significant limiting factor in their further development. Large companies and institutions are employing large-scale computer networks for communication and computation. The distributed applications running on these computer networks are diverse and deal with many tasks, ranging from internal control processes to presenting web content and to customer support.
Additionally, mobile computing is pervading these networks at an increasing speed: employees need to communicate with their companies while they are not in their office. They do so by using laptops, personal digital assistants, or mobile phones with diverse forms of wireless technologies to access their companies’ data.
This creates an enormous complexity in the overall computer network which is hard to control manually by human operators. Manual control is time-consuming, expensive, and error-prone. The manual effort needed to control a growing networked computer-system tends to increase very quickly.
A possible solution could be to enable modern, networked computing systems to manage themselves without direct human intervention. The Autonomic Computing Initiative (ACI) aims at providing the foundation for autonomic systems. It is inspired by the autonomic nervous system of the human body. This nervous system controls important bodily functions (e.g. respiration, heart rate, and blood pressure) without any conscious intervention.
In a self-managing autonomic system, the human operator takes on a new role: instead of controlling the system directly, he/she defines general policies and rules that guide the self-management process. For this process, IBM defined the following four functional areas:
- Self-configuration: Automatic configuration of components;
- Self-healing: Automatic discovery, and correction of faults;[5]
- Self-optimization: Automatic monitoring and control of resources to ensure the optimal functioning with respect to the defined requirements;
- Self-protection: Proactive identification and protection from arbitrary attacks.
CHARACTERISTICS:
1.Automatic:This essentially means being able to self-control its internal functions and operations.
2.Adaptive:An autonomic system must be able to change its operation
(i.e., its configuration, state and functions).
3.Aware:An autonomic system must be able to monitor (sense) its operational context as well as its internal state in order to be able to assess if its current operation serves its purpose.
MODEL

A fundamental building block of an autonomic system is the sensing capability (Sensors Si), which enables the system to observe its external operational context. Inherent to an autonomic system is the knowledge of the Purpose (intention) and the Know-how to operate itself (e.g., bootstrapping, configuration knowledge, interpretation of sensory data, etc.) without external intervention. The actual operation of the autonomic system is dictated by the Logic, which is responsible for making the right decisions to serve its Purpose, and influence by the observation of the operational context (based on the sensor input).
This model highlights the fact that the operation of an autonomic system is purpose-driven. This includes its mission (e.g., the service it is supposed to offer), the policies (e.g., that define the basic behaviour), and the “survival instinct”. If seen as a control system this would be encoded as a feedback error function or in a heuristically assisted system as an algorithm combined with set of heuristics bounding its operational space.
Autonomic Cloud Bursts on Amazon EC2
Cluster-based data centers have become dominant computing platforms in industry and research for enabling complex and compute intensive applications. However, as scales, operating costs, and energy requirements increase, maximizing efficiency, cost-effectiveness, and utilization of these systems becomes paramount. Furthermore, the complexity, dynamism, and often time critical nature of application workloads makes on-demand scalability, integration of geographically distributed resources, and incorporation of utility computing services extremely critical. Finally, the heterogeneity and dynamics of the system, application, and computing environment require context-aware dynamic scheduling and runtime management.
Autonomic cloud bursts is the dynamic deployment of a software application that runs on internal organizational compute resources to a public cloud to address a spike in demand. Provisioning data center resources to handle sudden and extreme spikes in demand is a critical requirement, and this can be achieved by combining both private data center resources and remote on-demand cloud resources such as Amazon EC2, which provides resizable computing capacity in the cloud.
This project envisions a computational engine that can enable autonomic cloud bursts capable of: (1) Supporting dynamic utility-driven on-demand scale-out of resources and applications, where organizations incorporate computational resources based on perceived utility. These include resources within the enterprise and across virtual organizations, as well as from emerging utility computing clouds. (2) Enabling complex and highly dynamic application workflows consisting of heterogeneous and coupled tasks/jobs through programming and runtime support for a range of computing patterns (e.g., master-slave, pipelined, data-parallel, asynchronous, system-level acceleration). (3) Integrated runtime management (including scheduling and dynamic adaptation) of the different dimensions of application metrics and execution context. Context awareness includes system awareness to manage heterogeneous resource costs, capabilities, availabilities, and loads, application awareness to manage heterogeneous and dynamic application resources, data and interaction/coordination requirements, and ambient-awareness to manage the dynamics of the execution context.
Comet service model has three kinds of clouds. One is highly robust and secure cloud and nodes in this cloud can be masters. In most application, data is critical and should be in the secure space. Hence, only masters in this cloud can treat the whole data for the application. Another is secure but not robust cloud. Nodes in this cloud can be workers and provide Comet shared coordination space. Robust/secure masters and secure workers construct a global virtualized Comet space. A master generates tasks which are small unit of work for parallelization and inserts them into Comet shared coordination space. Each task is mapped to a node on the overlay using its keyword and stored in the storage space of the mapped node. Hence, robust/secure masters and secure workers have Comet shared space in its architecture substrate. The master provides a management agent for tasks, scheduling and monitoring tasks. It also provides a computing agent because it can provide computing capability. A secure worker gets a task from the space one at a time, hence, it has a computing agent in its architecture. The workers consume the tasks and return the results back to the master through direct connection. The other cloud is for unsecured workers. Unsecured workers cannot access Comet shared space directly and also cannot provide their storage to store tasks but provide their computing capability. Hence they have only computing agent in their architecture. They request a task to one of the masters in the robust/secure network. Then the master accesses to the Comet shared space, gets a task and forwards it to the unsecured worker. When the worker finishes its task, then it sends the result back to the master.

Can you CHOP up autonomic computing?
The autonomic computing architecture provides a foundation on which self-managing information technology systems can be built. Self-managing autonomic systems exhibit the characteristics of self-configuring, self-healing, self-optimizing, and self-protecting; these characteristics are sometimes described with the acronym CHOP. This article discusses the self-CHOP attributes and, in particular, explains why they are not independent of each other and how self-managing autonomic systems can integrate the CHOP functions.
The acronym CHOP is shorthand for configure, heal, optimize, and protect, the fundamental aspects of autonomic computing technology. Autonomic systems are designed to address one or more of these aspects.
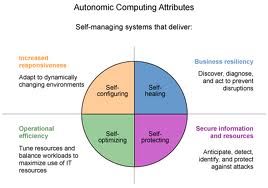
The attributes are defined as:
- Self-configuring – Can dynamically adapt to changing environments. Self-configuring components adapt dynamically to changes in the environment, using policies provided by the IT professional. Such changes could include the deployment of new components or the removal of existing ones, or dramatic changes in the system characteristics. Dynamic adaptation helps ensure continuous strength and productivity of the IT infrastructure, resulting in business growth and flexibility.
- Self-healing – Can discover, diagnose and react to disruptions. Self-healing components can detect system malfunctions and initiate policy-based corrective action without disrupting the IT environment. Corrective action could involve a product altering its own state or effecting changes in other components in the environment. The IT system as a whole becomes more resilient because day-to-day operations are less likely to fail.
- Self-optimizing – Can monitor and tune resources automatically. Self-optimizing components can tune themselves to meet end-user or business needs. The tuning actions could mean reallocating resources — such as in response to dynamically changing workloads — to improve overall utilization, or ensuring that particular business transactions can be completed in a timely fashion. Self-optimization helps provide a high standard of service for both the system’s end users and a business’s customers.
- Self-protecting – Can anticipate, detect, identify and protect against threats from anywhere. Self-protecting components can detect hostile behaviors as they occur and take corrective actions to make themselves less vulnerable. The hostile behaviors can include unauthorized access and use, virus infection and proliferation, and denial-of-service attacks. Self-protecting capabilities allow businesses to consistently enforce security and privacy policies.
A self-healing autonomic manager can detect disruptions in a system and perform corrective actions to alleviate problems. One form that those corrective actions might take is a set of operations that reconfigure the resource that the autonomic manager is managing. For example, the autonomic manager might alter the resource’s maximum stack size to correct a problem that is caused by erroneous memory utilization. In this respect, the self-healing autonomic manager might be considered to be performing self-configuration functions by reconfiguring the resource to accomplish the desired corrective action.
Self-healing and self-optimizing management could involve self-configuration functions (so, too, could self-protection). Indeed, it often may be the case that actions associated with healing, optimizing, or protecting IT resources are performed by configuration operations. Although self-configuration itself is a broader topic that includes dynamic adaptation to changing environments, perhaps involving adding or removing system components, self-configuration is also fundamental for realizing many self-CHOP functions.
Autonomic Manager

Figure illustrates that an autonomic manager might include only some of the four control loop functions. Consider two such partial autonomic managers: a self-healing partial autonomic manager that performs monitor and analyze functions, and a self-configuring partial autonomic manager that performs plan and execute functions, as depicted in the following Figure.
Integrating self-healing and self-configuring autonomic management functions

The first autonomic manager could monitor data from managed resources and correlate that data to produce a symptom; the symptom in turn is analyzed, and the autonomic manager determines that some change to the managed resource is required. This desired change is captured in the form of Change Request knowledge. The change request is passed to the self-configuring partial autonomic manager that performs the plan function to produce a change plan that is then carried out by the execute function. This scenario details the integration of self-healing and self-configuring autonomic management functions that was introduced earlier.
Self-CHOP describes important attributes of a self-managing autonomic system. Self-CHOP is a useful way to characterize the aspects of autonomic computing, but the four disciplines should not be considered in isolation. Instead, a more integrated approach to self-CHOP, such as this article describes, offers a more holistic view of self-managing autonomic systems.




































































